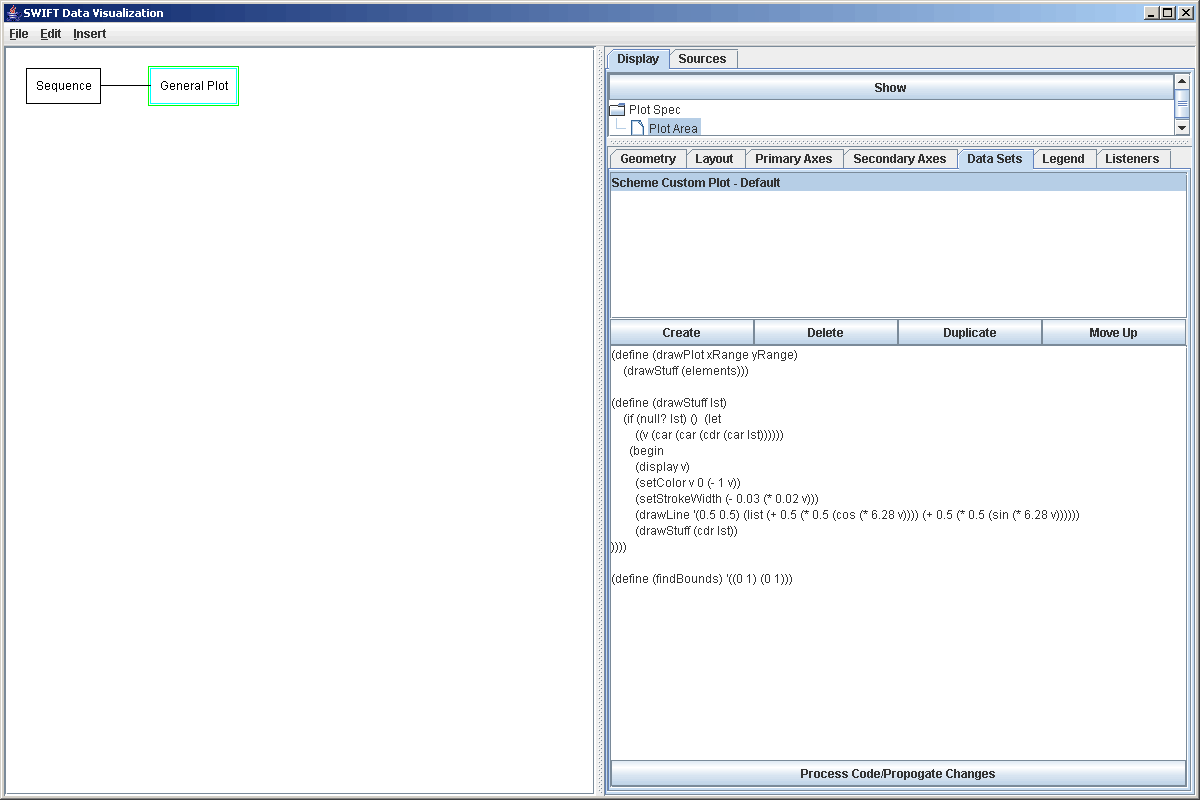
Using SVScheme
SWIFTVis includes an option for giving you greater flexibility without having to write components in Java. The way it works is that basically there is an interpreter for a version of Scheme built into the package. This is not a full implementation of Scheme as it only includes the features that are required for SWIFTVis. For example, there is no string processing in SWIFTVis because it doesn't deal with string data. You can get a general description of the abilities of SVScheme here. This page focuses o how you can use SVScheme in the context of SWIFTVis.
There are several places in SWIFTVis where you can use SVScheme. All of these have access to Scheme functions that you can write in the Options dialog box of SWIFTVis. If you go to File > Edit Options, you will see a tab labeled Scheme. Clicking on that tab gives you something that looks like the figure below. This figure shows some default code thatis provided for you. Currently this only uses a standard text area in Java. Perhaps a better editor can be put in in the future that does some syntax highlighting because matching parentheses in any version of Scheme can be a significant pain. You can always edit in your favorite Scheme editor (vi works well) and cut and paste into SWIFTVis.
As was mentioned above, the functions that appear in this dialog box can be used by Scheme code at any point in SWIFTVis. There are 4 main places where SVScheme code can be used in SWIFTVis. The first, and most obvious, is in the various formulas in SWIFTVis. You can follow the scm function call with a SVScheme function call to perform more complex calculations or boolean expressions. This use of SVScheme is the least desirable as it imposes a significant performance hit to invoke the SVScheme environment for each element. For small data sets you will likely never notice this hit, but it could become significant for larger data sets.
In order for the scheme formulas to be truly useful, they have to be able to access the data elements. In the formulas, there are 6 ways to access data. The values p and v are bound to lists that hold the parameters and value of the current element. So (car v) gives you the first value of the element being used for the formula. If you want integer based access you can use the functions (param pnum) and (value vnum). These work like p[pnum] and v[vnum] in a formula. If you want to pull elements from sources other then the first one, d[0], you need to use the (element [source=0 [offset=0]]) function. This will return one element as a list of the form ((p[0] p[1] ...) (v[0] v[1] ...)) from the specified source with the specified offset. Both source and offset are optional and default to 0. So calling (element) will just give you the list (p v), while calling (element 1) will give you the current element from the second source. Also, if a formula is using groups, you can use the function (special which [source=0]) to grab one of the special data elements. If you call (special 0) you get the list ((p'[0] p'[1] ...) (v'[0] v'[1] ...)). Calling (special 1) is the double primed element.
The second place that you can use SVScheme is in the creation of custom filters. To do this, simply insert a filter and select the "Scheme Filter" option. This is a filter that processes elements based on Scheme code that the user can input.
The code written here has access to all of the functions in the Option Scheme code and
can call on a function (elements [source=0]) which returns all of the elements of the
specified source as a list. If no source is provided, it defaults to 0. Each element of the list has the form ((p[0] p[1] ...) (v[0] v[1] ...))
and gives the parameters and values of the elements of the specified source.
The Scheme code must have a function (filterElements numSources) that will be passed the
number of sources for this filter. This function should return a list of elements of the
same format as what the elements function returns. That will be used as the output. By
default you are provided with a method that returns a null list so no elements go throughs.
To do a transformation, you can write a function that transforms an element list and apply
it to the elements using the map function that is given by default in the Options pane. To select
and transform use the selectMap with two functions that is provided for you.
You can also write functions of the form (parameterDescription pnum) and
(valueDescription vnum) that should return quoted names for the specified parameters and values.
What is passed in will be integers that are 0 referenced. If these functions are not written,
default names will be provided. Note the SVScheme does not have string processing so the quoted
names can only be single words.
An example for a possible valueDescription function might be the following:
(define (valueDescription vnum)
(cond
((= vnum 0) 'time)
((= vnum 1) 'a)
((= vnum 2) 'e)
(else 'error)))
The figure below shows a SWIFTVis screen with a Scheme Filter that is pulling data from a Binary Position source. The code that is written will select all of the elements for test particles with numbers between 10 and 20 and will only propogate t, a, e, and i while adding an extra element for the period in years. Notice that in practice the append function should probably be put in the Options area, but here we are leaving it in so that you can see it. We do use the selectMap function provided with SVScheme. When possible, you should use the built-in functions as they are often more efficient. In the case of selection and mapping functions they overcome the fact that SVScheme does not identify tail recursion and allow you to use larger datasets without overflowing the stack.
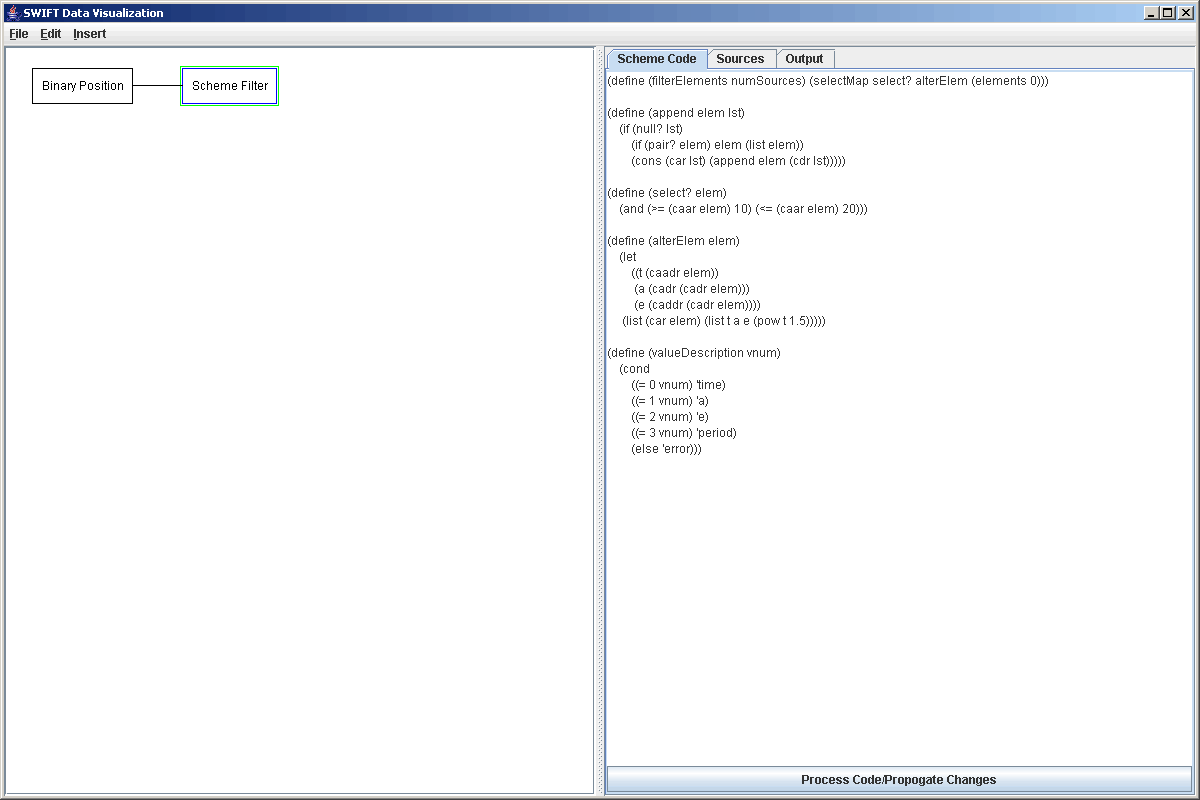
Of course, this example could be accomplished with a selection filter followed by a function filter. There are things that the Scheme Filter can do that other provided filters can't though and those are the things for which the Scheme Filter is best suited. For example, the normal filters in SWIFTVis only work well with elements that have the same number of values and parameters. This is fine with the standard SWIFTVis sources, because they all produce rather uniform data. However, you might happen to read a text file where different lines have different numbers of entries and you only care about lines with a certain number of entries. No standard formula or filter can help you pick only those elements. With a Scheme Filter it is easy though. Simply use the select function and pass it a function that checks either (length (car elem)) or (length (cadr elem)) depending on whether you care about the number of parameters or the number of values.
As one might expect, the use of SVScheme in this context does have a memory and performance cost. It should not be too significantly slower than the use of other filters, it can be in some cases and can use significantly more memory in some cases. This is because it can't reuse elements like the selection filter, key selection filter, and thinning filter. In this context though, using SVScheme should not be significantly slower than using regular formulas and for filters like the function filter which don't reuse elements the memory overhead isn't nearly as significant. If you need custom filtering on large data sets you will be better off writing your own filters in Java or requesting that one be added. This rule applies generally to all the sources and plot styles that are described below as well.
The third place that you can use SVScheme is in the Scheme Source. In those situation where the General Data source isn't actually general enough for you, the Scheme Source can be made to read pretty much whatever you want from one file. You have to write a (readElements numFiles) function that should return the same format of list that the Scheme Filter returned. There are a number of different functions that you can use to read in values, depending on whether your file in text or binary. If it is text, you should use (readText [file=0]) and (readLine [file=0]) as well as (skipWord [file=0]) and (skipLine [file=0]). The (readText [file=0]) function reads in a single number from the specified file, first one by default, and returns it. An error will occur if what is read isn't a number so you would need to use (skipWord [file=0]) to jump over non-numeric parts of the file. The (readLine [file=0]) function reads a whole line and breaks it up across whitespace, then converts it to a list of numbers that is returned. Again, there is an error if there is non-numeric data. The (skipLine [file=0]) function just reads a whole line and throws it away. Remember to use the (begin ...) "function" in Scheme when skipping things.
If the file that you are reading from is a binary file, you should use the functions (readInt2 [file=0]), (readInt4 [file=0]), (readInt8 [file=0]), (readReal4 [file=0]), (readReal8 [file=0]), (readInt2XDR [file=0]), (readInt4XDR [file=0]), (readInt8XDR [file=0]), (readReal4XDR [file=0]), and (readReal8XDR [file=0]). The names of these describe fairly well what they do.
There is also an (EOF [file=0]) function that returns whether or not you have reached the end of the file. To help you with reading (and possibly other things), two other functions have been provided in the general SVScheme framework. They are (buildList boolFunc|num elemFunc) and (buildListFromLists boolFunc|num listFunc). They both take either a function of zero arguments or a number as the first argument and as long as the function returns true or as many times as is specified, the second function is called and what it returns is added to the list. In the first case, whatever is returned is used as an element of a list that is built and returned. In the second case, the return value is assumed to be a list and all the elements of that list are added in.
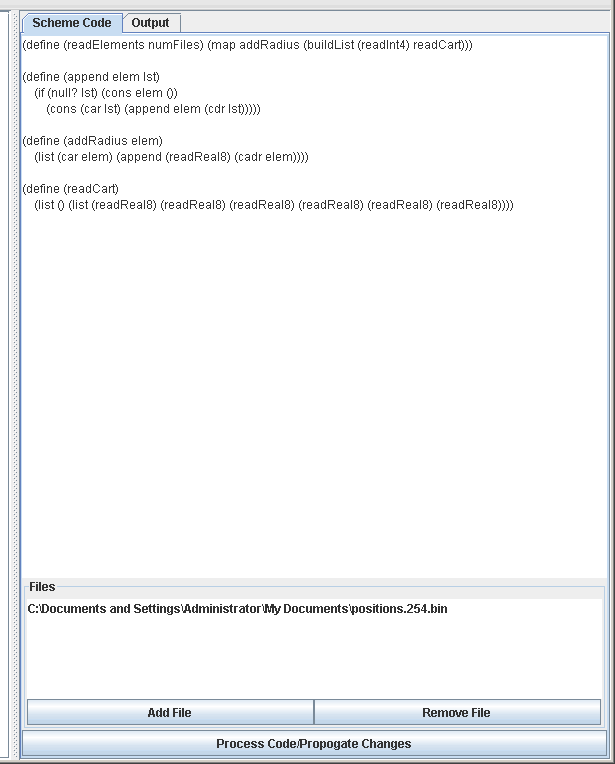
To see how we can use these things, let's look at some different examples such as reading a bin.dat file or a different binary file that is the result of some rings simulations. Both of these are used as examples because the General Data source does not have the power to do quite what we want. In the case of the bin.dat, the problem is that the number of bodies in the header for each timestep is one larger than the actual number of bodies written and the General Data source doesn't allow mathematical expressions in the descriptions of how many times things should be read. For the other file, this was used in the General Data source tutorial, but we had to ignore some of the data in the file. The particular file starts with the number of particles in the simulation, followed by records of x, y, z, vx, vy, vz. After that are all the radii for the particles. The General Data source can't read the radii at the end because it can't append to elements it has already read. We'll see here how the Scheme Source can get around both of these problems. Of course, there is already a Binary Position source that you can use to read bin.dat files that is much more efficient than what is presented here, but this is shown to you as an example of what you can do.
The bin.dat file has a fairly simple format, one timestep after another, and each timestep includes a number of different records. Because we want to read multiple records at once we will use the buildListFromLists function and the arguments will be EOF and a function we will write that will return a list of all of the elements in a single timestep. We'll call it readTimestep. The code for this is shown in the screen shot below. Note that there are places where we use begin and read in some extra int*4s. These are due to the fact that the normal bin.dat is written with Fortran which likes to put headers and footers on all records.
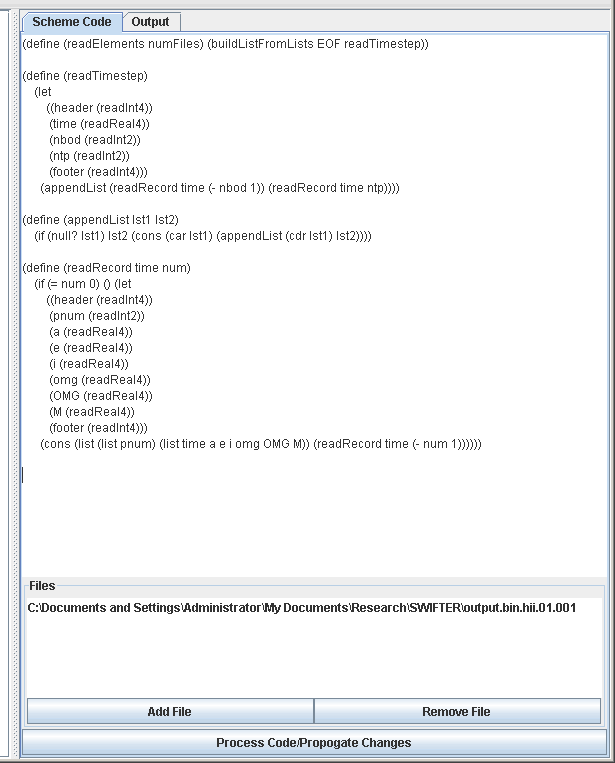
To help make sure the code worked (which it didn't the first time it was written), we replaced EOF with 10. That way we can see a quick sample of just a few elements if the function works properly. For the rings data set, we have a slightly different issue in that we want to read in a number of elements of data, then add more data later. For this, we will use the buildList function to read in the original data, then use map to read in the new data and add the radii to all of the original elements. The figure below shows a screen shot of the code where this is done.
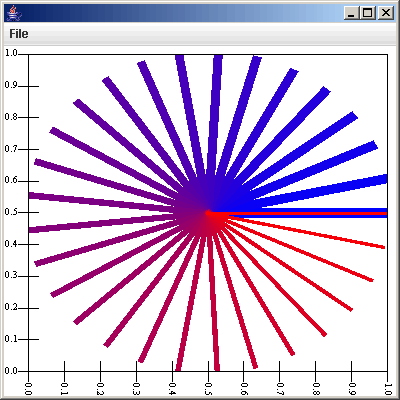
The fourth, and last place that you can use SVScheme is to make custom plot styles using the Scheme Plot Style. Like a filter, this will walk through all of the elements and in this case you can give it commands to draw different things to the plot surface. Because the plotting commands don't have return values, you will likely want to use the (begin ...) statement to string commands together. You can use the (elements [source=0]) to get hold of all the data coming from a given source. There are a number of functions provided for you to draw with: (setColor red green blue [alpha=1]), (setStrokeWidth width), (drawLine p1 p2), (fillPoly p1 p2 ...), (drawPoly p1 p2 ...), (fillEllipse p w h), (drawEllipse p w h). You have to provide a function called drawPlot and a function called findBounds. Neither of those functions takes arguments. The second one needs to return a list of pairs giving the min and max for the primary and secondary axes respectively.